Difference between revisions of "Multilayer perceptron"
(New page: == General == A multilayer perceptron is a feedforward artificial neural network. This means the signal inside the neural network flows from input layer passing hidden layers to output la...) |
|||
| Line 3: | Line 3: | ||
A multilayer perceptron is a feedforward artificial neural network. This means the signal inside the neural network flows from input layer passing hidden layers to output layer. While training the error correction of neural weights are done in the opposite direction. This is done by the backpropagation algorithm. |
A multilayer perceptron is a feedforward artificial neural network. This means the signal inside the neural network flows from input layer passing hidden layers to output layer. While training the error correction of neural weights are done in the opposite direction. This is done by the backpropagation algorithm. |
||
| − | == Error of network == |
+ | == Error of neural network == |
If the neural network is initialized by random weights it has of course not the expected output. Therefore training is necessary. While supervised training known inputs and their corresponded output values are presented to the network. So it is possible to compare the real output with the desired output. The error is described as the following algorithm: |
If the neural network is initialized by random weights it has of course not the expected output. Therefore training is necessary. While supervised training known inputs and their corresponded output values are presented to the network. So it is possible to compare the real output with the desired output. The error is described as the following algorithm: |
||
| Line 16: | Line 16: | ||
== Backpropagation == |
== Backpropagation == |
||
| − | The learning algorithm of a single layer perceptron is easy compared to a multilayer |
+ | The learning algorithm of a single layer perceptron is easy compared to a multilayer perceptron. The reason is that just the output layer is directly connected to the output, but not the hidden layers. Therefore the calculation of the right weights of the hidden layers is difficult mathematically. To get the right delta value for changing the weights of hidden neuron is described in the following equation: |
| − | <math>\Delta w_{ij}= -\alpha {\partial E \over \partial w_{ij}} = \alpha \delta_{j} x_{i}</math> |
+ | <math>\Delta w_{ij}= -\alpha \cdot {\partial E \over \partial w_{ij}} = \alpha \cdot \delta_{j} \cdot x_{i}</math> |
:<math>\Delta w_{ij}</math> delta value <math>w_{ij}</math> of neuron connection <math>i</math> to <math>j</math> |
:<math>\Delta w_{ij}</math> delta value <math>w_{ij}</math> of neuron connection <math>i</math> to <math>j</math> |
||
| Line 26: | Line 26: | ||
:<math>t_{j}</math> desired output of output neuron <math>j</math> |
:<math>t_{j}</math> desired output of output neuron <math>j</math> |
||
:<math>o_{j}</math> real output of output neuron <math>j</math>. |
:<math>o_{j}</math> real output of output neuron <math>j</math>. |
||
| + | |||
| + | == Programming solution of backpropagation == |
||
| + | |||
| + | In this PHP implementation of multilayer perceptron the following algorithm is used for weight changes in hidden layers: |
||
| + | |||
| + | <math>s_{kl} = \sum^{n}_{l=1} w_{k} \cdot \Delta w_{l} \cdot \beta</math> |
||
| + | |||
| + | <math>\Delta w_{k} = o_{k} \cdot (1 - o_{k}) \cdot s_{kl}</math> |
||
| + | |||
| + | <math>w_{mk} = w_{mk} + \alpha \cdot i_{m} \cdot \Delta w_{k}</math> |
||
| + | |||
| + | :<math>\alpha</math> learning rate |
||
| + | :<math>\beta</math> momentum |
||
| + | :<math>k</math> neuron k |
||
| + | :<math>l</math> neuron l |
||
| + | :<math>m</math> weight m |
||
| + | :<math>i</math> input |
||
| + | :<math>o</math> output |
||
| + | :<math>n</math> count of neurons |
||
| + | |||
| + | To avoid overfitting of neural network the training procedure is finished if real output value has a fault tolerance of 1 per cent of desired output value. |
||
Revision as of 15:31, 13 January 2008
General
A multilayer perceptron is a feedforward artificial neural network. This means the signal inside the neural network flows from input layer passing hidden layers to output layer. While training the error correction of neural weights are done in the opposite direction. This is done by the backpropagation algorithm.
Error of neural network
If the neural network is initialized by random weights it has of course not the expected output. Therefore training is necessary. While supervised training known inputs and their corresponded output values are presented to the network. So it is possible to compare the real output with the desired output. The error is described as the following algorithm:
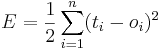
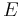 network error
network error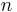 count of input patterns
count of input patterns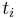 desired output
desired output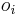 calculated output
calculated output
Backpropagation
The learning algorithm of a single layer perceptron is easy compared to a multilayer perceptron. The reason is that just the output layer is directly connected to the output, but not the hidden layers. Therefore the calculation of the right weights of the hidden layers is difficult mathematically. To get the right delta value for changing the weights of hidden neuron is described in the following equation:
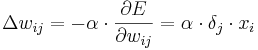
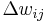 delta value
delta value 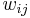 of neuron connection
of neuron connection 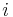 to
to 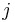
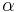 learning rate
learning rate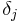 the error of neuron
the error of neuron 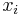 input of neuron
input of neuron 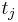 desired output of output neuron
desired output of output neuron 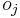 real output of output neuron .
real output of output neuron .
Programming solution of backpropagation
In this PHP implementation of multilayer perceptron the following algorithm is used for weight changes in hidden layers:
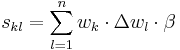
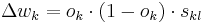
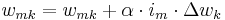
- learning rate
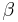 momentum
momentum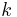 neuron k
neuron k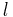 neuron l
neuron l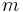 weight m
weight m- input
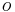 output
output- count of neurons
To avoid overfitting of neural network the training procedure is finished if real output value has a fault tolerance of 1 per cent of desired output value.